Big Data
Drowning in a sea of data
We’re told to collect as much data from our processes as we can, and there’s practically infinite storage space in the cloud—but how do you make sense of all this data?

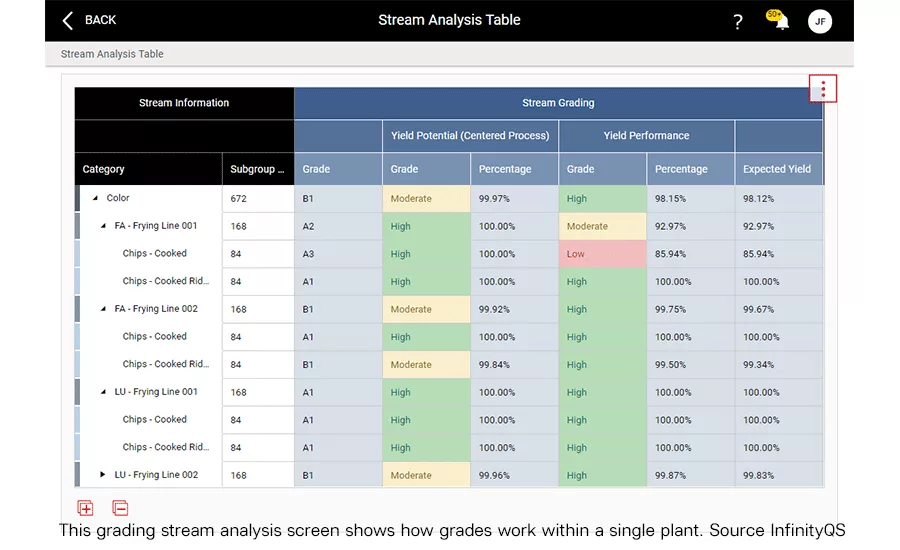
This grading stream analysis screen shows how grades work within a single plant.
Source: InfinityQS
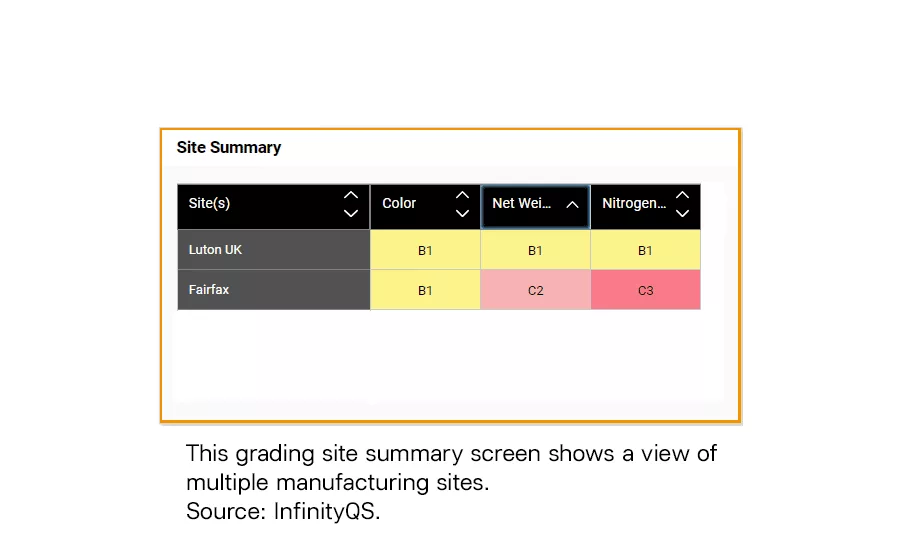
This grading site summary screen shows a view of multiple manufacturing sites.
Source: InfinityQS
With automation and the Industrial Internet of Things (IIoT), it’s now easier than ever to collect data and monitor production—all this in the name of managing food quality and food safety. But, with multiple sites and lines supplying data around the clock, any staff would be all but overwhelmed—without a direction in where to focus their process management efforts.
With the likes of the cloud providers like IBM, Microsoft and Amazon, the lure of big data and the solutions that it can potentially provide often has the engineering staff asking, what if we collect this data and that data, and more data—but is the solution to collect terabytes and petabytes of big data, hoping to find a needle in a haystack with AI, a good idea? Isn’t there a more sensible approach to collecting the data you need to improve the manufacturing process, food quality and food safety?
Time was, collecting data was used as a feedback mechanism to control the process. It closed the loop, and as long as the set points were established and hysteresis was at a minimum, the process would run smoothly, turning out consistent product. Collected data from sensors was pretty specific, and well defined—and generally small. However, controls for a chemical process may not always experience the issues a food process—namely inconsistency of ingredients or inputs.
So, data about a food or beverage process is necessarily complicated—especially when it’s needed to control quality and meet food safety/regulatory standards. Doug Fair, COO at InfinityQS has had a lot of experience helping food processors discover what data they really need to collect and what to do with it once they have it. For more than 30 years, Fair has worked with hundreds of plants around the world to analyze quality data on the plant floor—and beyond—to inspire exponential improvements and millions in savings. I asked Doug to sort out some practical solutions for our readers.
FE: Some engineers may think that if the equipment and software are available, why not collect as much data as possible “because we can.” So before going any further, how should engineering be communicating with the quality staff, operations and the food safety group?
Doug Fair: Many manufacturers try to collect as much data as possible because, up until recently, they were starved for information. Their hope is that the collected datasets will show them how production processes are running and give a picture of product quality. But the truth is, collecting data—every millisecond, around the clock—for the sake of having it does not lead to process improvement. The insight gleaned from the data is what actually benefits the business. Engineers should communicate the need to convert data into intelligence—by aggregating, summarizing, and analyzing it through statistical techniques, then repeating the process on a regular basis.
FE: How should the processor decide on what data to collect? How does a processor decide what data not to collect—what is just noise?
Fair: I would not say that certain datasets are more important, while others are just noise. Sometimes the most innocuous datasets can reveal millions of dollars in savings. What is more imperative is the frequency of collection and the evaluation of data afterwards. Food producers should consider the following first before any data collection:
- Why do we need to gather this data?
- Is this a short-term data collection necessary to solve a problem?
- Is this data required to fulfill a long-term strategic goal?
- How will the data be used after it is collected?
- Who will evaluate that data?
- How will the data be evaluated?
- What is a reasonable, rational amount of data to collect?
- How frequently do we need to collect the data?
- Do we really need to collect data every few milliseconds?
- If so, what purpose would it serve?
- How will the data be used?
By asking these questions, they can form rational data collection plans with reasonable frequencies of data sampling, rather than just collect terabytes of numbers that no one has time to review. After all, collected data must ultimately serve a purpose.
FE: How does a processor know that the selected data for monitoring will benefit fine-tuning the process to get the best continuous quality?
Fair: My experience is that the Pareto Principle applies here. That is, about 80% of the benefit is typically found in 20% of the data. I’ve also experienced that most plant-based quality experts are pretty good at identifying where the issues are, and what will benefit from fine-tuning. However, if that information is unknown, or if a plant just wants to eliminate opinions and drive quality actions strictly based on data, then more features should be evaluated and more data should be collected—for a short period of time.
After that time has passed and enough data has been collected, quality professionals should closely scrutinize the data to identify the 20% that requires monitoring. There are lots of analysis tools available to help discern what should be monitored for fine-tuning, and it can be challenging. However, without doing proper data analysis, the result can be an expensive guessing game where opinion and hearsay override fact and evidence.
FE: How should a data collection/quality system be set up to show quality teams what to fix first? How about maintenance teams?
Fair: A data collection and/or quality system should provide a way for both quality teams and maintenance teams to quickly look across their operations and prioritize areas of improvement. One such way is by providing a “grade” for a specific production line, process, product, or feature. Using aggregated data, the system can automatically apply statistical analysis to provide a simple letter-number combination that shows how an aspect of operations is performing—and if it is living up to its full potential.
Such grades offer manufacturers a new way of looking at process performance, not only by quickly pinpointing what requires attention, but also what kind of attention is needed. If a line or process is not performing well, teams should be able to then drill down and identify the root cause. For example, a quality issue may simply require correcting some equipment settings. These “easy wins” can be addressed immediately using little time and few resources, but can deliver big impact.
On the other hand, some projects may require more expertise and resources. After digging into the root cause of an issue, a company may find that it needs to replace outdated or broken equipment. Knowing the effort required enables manufacturers to effectively plan process improvement budgets. They do not have to look for a needle in a haystack.
FE: How should a data collection/quality system be set up to improve processes at individual plants?
Fair: Collected data should be stored in a centralized data repository. Only then can manufacturers perform the comparisons and analyses needed to turn data into intelligence. Teams within plants should regularly set aside time to do recurring “information extraction” meetings.
In these meetings, managers, engineers, and quality professionals step back from their daily tasks to analyze aggregated data from the plant floor. They compare performance across lines and product codes. The goal is to better understand what the data is telling them and uncover information that they never knew was there.
FE: How should such a system be set up to monitor more than one plant if a processor has more than one facility? Can a quality system be used to compare one plant against another? Is this a good idea? Who should have access to the data?
Fair: Thanks to cloud computing, manufacturers can collect data from multiple plants and suppliers and save that data centrally, in the cloud. With all the data in one place, manufacturers can aggregate, summarize,and roll-up the data in a variety of different ways, giving executives meaningful insight across all operations. Here, they can compare quality performance between lines, product codes, regions, suppliers, and plants—which can uncover enormous opportunities for cost reduction and quality improvement.
In fact, a global view of quality with the aim of continuous process improvement can be a distinct competitive advantage for today’s food manufacturers. For instance, best practices from well-performing plants can be rolled out and made standard practice, while high-level quality issues can be prioritized as projects for Six Sigma teams. Moreover, such enterprise visibility and plant-to-plant comparisons can help ensure standardization and consistency of product manufacturing.
The grading method mentioned earlier can be applied at the executive level as well. With the simple letter-number combinations, executives can see, at a glance, how each site is performing. They can then prioritize global improvement opportunities based on which ones will generate the most positive impacts in the shortest amount of time—in process performance, product quality, and the bottom line.
FE: Indeed, many food safety systems have been called food safety/quality management systems. What do food and beverage processors need to know when selecting a FS/QM system?
Fair: It’s true that food safety systems and food quality systems are commonly referred to synonymously. The two are closely related, yet subtly different. Both require data to be gathered on the shop floor and in labs. Both require careful study and analysis to glean information from collected data. Analyzing net contents is typically considered a quality management action, yet reviewing HACCP data and validating that cleanliness checks have been performed are actions typically associated with food safety. Yet foundationally, food safety and food quality management systems are similar as each relies on data collection and analysis tasks. Therefore, both food safety and quality management needs should be supported in a single system, so there should be no need to invest in multiple systems. A single system should support both purposes.
When selecting a food safety/quality management system, you’ll likely want to deploy the system quickly while minimizing IT costs. To do so, invest in modern software-as-a-service (SaaS) systems. SaaS products allow you to deploy quickly, not only across your plants, but also to your suppliers, allowing real-time quality data to be collected and analyzed across the value chain.
When selecting a food safety/quality management system, look for flexibility. The system should support automated data collection from laboratory equipment as well as from shop-floor machinery. Importantly, the system should be simple for an operator or lab tech to work with. It should include automated reminders for when data collection is required, and generate alerts when issues occur or when data collection has not been performed. Validation and verification checks should be simple and include checklists and codes that don’t require lab techs and operators to type in information.
Lastly, look for a system that supports a wide variety of analysis capabilities. Ultimately, we gather data because we want information. And that information will be revealed through the use of analysis tools—but they shouldn’t be difficult to understand. Analysis tools should appeal not only to quality professionals, but to managers, directors, and even C-suite individuals. Basically, the system should provide intuitive information to any individual in your company, and it shouldn’t require an engineer or quality professional to provide interpretation services.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!







